
Unser Ziel bei Quadient ist es, die Kommunikation und den Informationsaustausch für Benutzer über verschiedene Plattformen hinweg zu vereinfachen, indem wir Prozesse automatisieren und ihnen so wertvolle Zeit sparen. Eine der Aktivitäten, die Kunden manuell durchführen mussten, ist das Extrahieren von Informationen aus Dokumenten.
Es gibt mehrere Algorithmen, die Informationen aus Dokumenten extrahieren. Dieser Beitrag richtet sich an Personen, die nach einer schnellen und kostengünstigen Möglichkeit suchen, Daten aus Dokumenten zu extrahieren, ohne sich mit den Feinheiten der Datenextraktion befassen zu müssen oder umfassende Kenntnisse der künstlichen Intelligenz zu benötigen.
Wie entscheidet man?
Marktführer im Softwarebereich bieten fertige Lösungen zur Datenextraktion an. In diesem Abschnitt werden Dienste von Microsoft, AWS, Google und Rossum verglichen. In der folgenden Tabelle können Sie nachlesen, welche Anbieter unsere Anforderungen hinsichtlich der von uns festgelegten Kennzahlen erfüllt haben.
Die einzige Lösung, die unsere Anforderungen an die Extraktionsgenauigkeit nicht erfüllte, war AWS. Für unsere Zwecke – Erkennung von Informationen aus Rechnungen – haben wir uns für Microsoft entschieden. Ausführlichere Informationen wurden bei unserem MeetinQ Nr. 2 mit dem Titel „KI in der Entwicklung“ vorgestellt. Hier die Ergebnisse von Microsoft zur Rechnungserkennung.
Preis: Bei vorgefertigten Modellen liegt der Preis für anerkannte Dokumente bei etwa 10 $ für 1000 Seiten. Für benutzererstellte Modelle beträgt der Preis ungefähr 50 $ für 1000 Seiten. Der Preis sinkt mit der Anzahl der verarbeiteten Seiten. Einen ungefähren Betrag können Sie im Azure-Rechner berechnen.
Ausgabe: Alle Anbieter, einschließlich Azure, geben Ergebnisse im JSON-Format zurück, wodurch es möglich wird, Informationen in Anwendungsobjekte zu serialisieren und mit ihnen weiterzuarbeiten. Spezifische Informationen zu JSON-Elementen finden Sie in der Dokumentation.
Genauigkeit: Die Informationserkennung von Microsoft und anderen Anbietern außer AWS ergab interessante Ergebnisse. Wesentliche Rechnungsdaten wie Adressen und Rechnungsbeträge werden in den meisten Fällen bereits aus den Rechnungen extrahiert. Dabei werden einzelne Beträge, aus denen sich die Rechnung zusammensetzt, die sogenannten „Einzelposten“, erkannt und tabellarisch dargestellt. Die Zuversicht, mit der der Anbieter bestimmte Informationen erkannt hat, wird in Form von „Vertrauen“ ausgedrückt. Es ist zu beachten, dass diese Daten nicht absolut sind, da die Anbieter die Genauigkeit mit ihren Algorithmen berechnen. Im Allgemeinen führt ein höheres „Vertrauen“ zu genauer erkannten Informationen. Wir haben die Genauigkeit vorgefertigter Abrechnungsmodelle von Azure untersucht, die zur allgemeinen Rechnungserkennung verwendet werden können. Wenn wir die Genauigkeit bestimmter Kundenrechnungen erhöhen möchten, könnten wir unsere eigenen Modelle trainieren.
Modelle: Wie aus den vorhergehenden Absätzen hervorgeht, stellt Microsoft vortrainierte Modelle bereit, die zur Informationsextraktion verwendet werden können. Neben Rechnungsvorlagen gibt es Quittungen, Ausweisdokumente (Reisepass, Personalausweis etc.), Krankenversicherungskarten, Steuerformulare und mehr.
Azure Extraction in der Praxis
Zur Datenextraktion müssen lediglich zwei Ressourcen geschaffen werden: Storage als Datenspeicher und Document Intelligence zur Dokumentenerkennung. Der Prozess der Ressourcenerstellung ist intuitiv.
Document Intelligence Studio
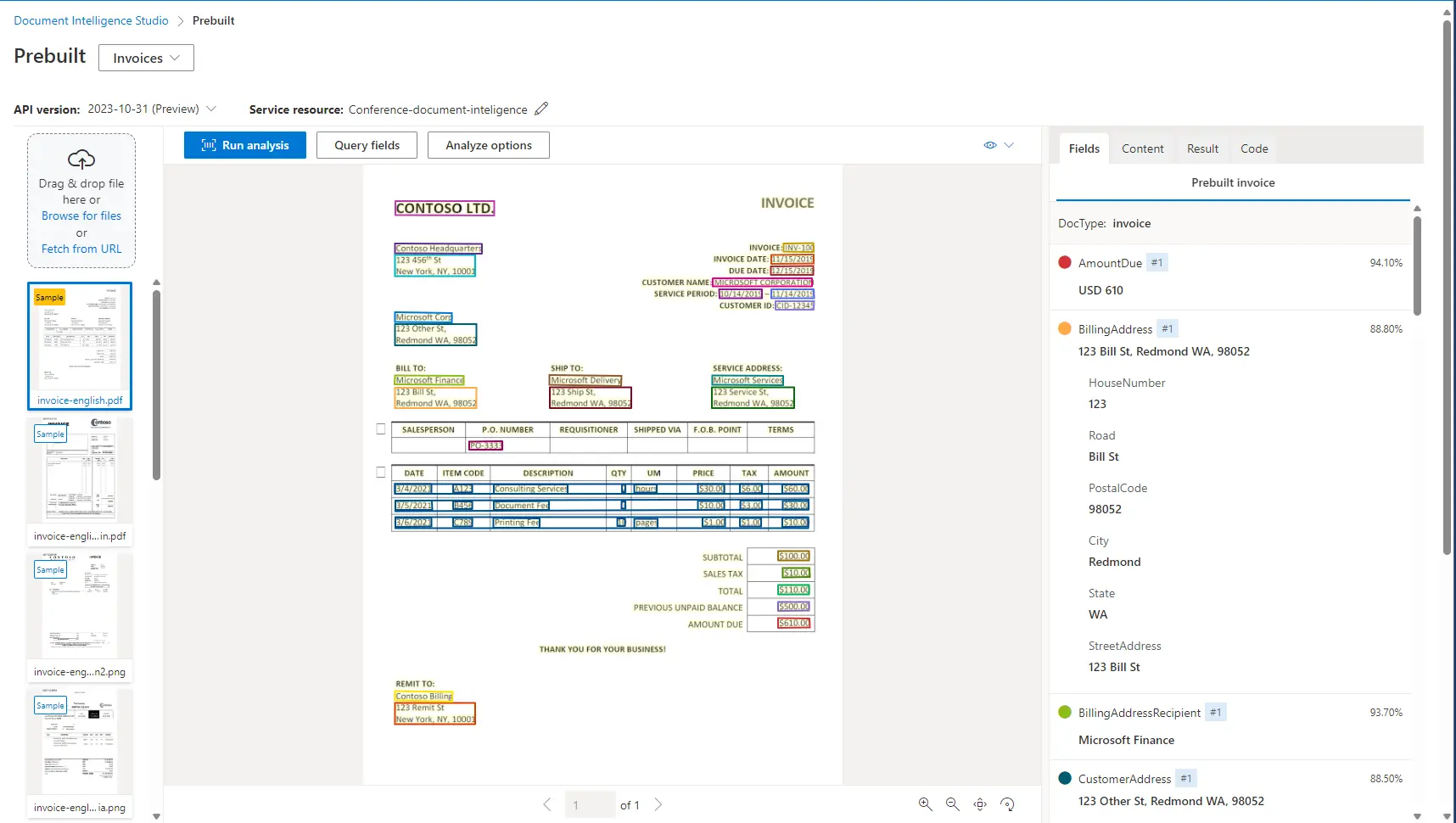
Azure bietet eine Benutzeroberflächenschnittstelle zur Datenextraktion. Wir können die für unsere Zwecke benötigten Varianten einfach und schnell testen. Die Schnittstelle findest du, indem du die Document Intelligence-Ressource auf der Hauptseite unter dem Namen Document Intelligence Studio öffnest. Hier ein Beispiel einer erkannten Rechnung: Neben der Dokumentenerkennung können wir auch individuelle Modelle in der Benutzeroberfläche trainieren und testen.
Integration in My Application
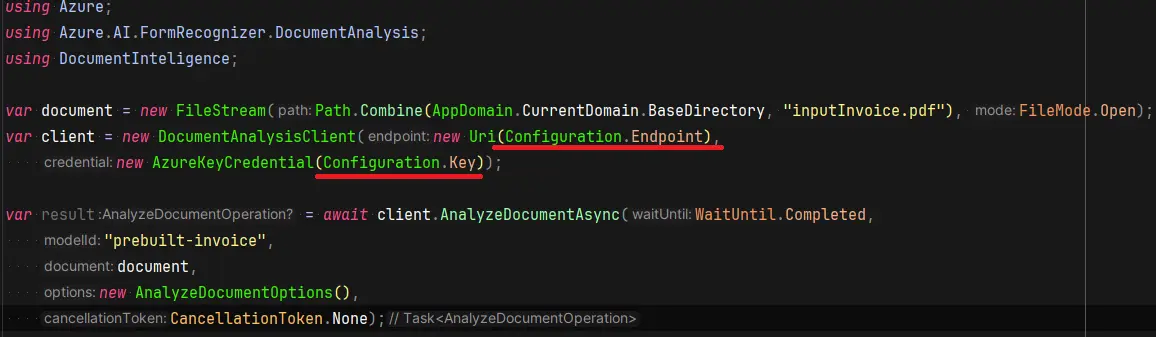
Microsoft bietet Pakete für C#, Python, Java und JavaScript. Für die Verwendung in anderen Sprachen steht eine REST-API zur Verfügung. Hier ist ein Beispiel für C#. Um einen Client aus dem Paket zu erstellen, müssen die Quelladresse und die Autorisierungsinformationen angegeben werden. Alles ist im Azure-Portal unter der erstellten Ressource zu finden. Die Autorisierung kann auch mithilfe einer verwalteten Identität und anderer Autorisierungsmechanismen erfolgen.
Mögliche Probleme
Ich hoffe, aus den obigen Zeilen ist klar geworden, dass das Extrahieren von Informationen aus Dokumenten intuitiv ist und auch ohne Kenntnisse über künstliche Intelligenz und Extraktionsalgorithmen in unsere Anwendungen integriert werden kann. Ich möchte alle motivieren, vorhandene Lösungen zu erkunden, die das Niveau unserer Anwendungen erhöhen und die Nutzung vereinfachen können. Während der Integration sind uns einige Probleme aufgefallen, die ich erwähnen möchte.
Geschwindigkeit: Bei der Verarbeitung einer großen Anzahl von Dokumenten muss die Skalierung berücksichtigt werden. Die Verarbeitung eines einseitigen Dokuments dauert weniger Sekunden.
Serialisierung: Das Ergebnis mit den extrahierten Daten kann nicht erneut in ein vom Azure-Paket in C# bereitgestelltes Objekt serialisiert werden. Dies kann beispielsweise beim Testen ein Problem sein, wenn wir JSON-Daten nicht wieder in einem Objekt darstellen können, das wir testen möchten.
Pakete: Für C# gibt es derzeit zwei gleichwertige Pakete. Das DocumentIntelligence- Paket wurde dem FormRecognizer- Paket hinzugefügt. In Zukunft wird das FormRecognizer-Paket wahrscheinlich ersetzt, was jedoch kein Problem darstellen sollte, da beide abwärtskompatibel sind.
Rechnungsformat: Unternehmen, die Rechnungen verarbeiten, benötigen standardisierte Formate wie CII, UBL usw. als Eingabe. Das Ergebnis der erkannten Rechnung muss in unserer Anwendung in diese Formate konvertiert werden.