
V Quadientu se snažíme uživatelům zjednodušit komunikaci a sdílení informací k širokému okruhu lidí. Zautomatizovat procesy, které by uživatel musel dělat manuálně a tím šetřit jejich cenný čas. Jedna z činností, kterou zákazníci museli dělat manuálně, je vyplňování informací z dokumentu.
Existuje celá řada algoritmů, které získávají informace z dokumentu. Tento příspěvek cílí k lidem, kteří hledají způsob, jak rychle a finančně dostupně extrahovat data z dokumentů bez vhledu do problematiky datové extrakce a bez větších znalostí umělé inteligence.
Jak si vybrat?
Datovou extrakcí, se zabývají lídři SW trhu, přinášející hotové řešení. Tato část porovnává služby Microsoftu, AWS, Googlu a Rossumu.
V tabulce níže lze vidět jací poskytovalé splňovali naše požadavky pro metriky, které jsme si určili.
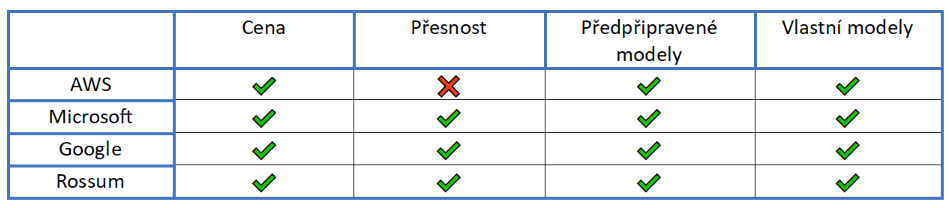
Jediné řešení, které kvůli přesnosti extrakce nevyhovovalo požadavkům, je řešení společnosti AWS. Pro naše účely – rozpoznávání informací z faktury – jsme si vybrali Microsoft. Podrobnější informace byly prezentovány na našem MeetinQ #2 s názvem AI v developmentu. Zde jsou výsledky společnosti Microsoft pro rozpoznávání faktur.
Cena: Pro předpřipravené modely, které probereme za chvíli, se cena rozpoznaných dokumentů pohybuje okolo 10$ za 1000 stránek. Pro modely vytvořené uživatelem je cena přibližně 50$ za 1000 stránek. Cena klesá s počtem stránek, které zpracujeme. Přibližnou sumu si lze spočítat v Azure kalkulačce.
Výstup: Všichni poskytovatelé včetně Azure vracejí výsledky v JSON formátu, takže lze informace serializovat do aplikačních objektů a dále s nimi pracovat. Konkrétní informace prvků JSONu lze vidět v dokumentaci.
Přesnost: Rozpoznání informací Microsoftu, ale i dalších poskytovatelů s výjimkou AWS dosahovalo zajímavých výsledků. Z faktur jsou ve většině případů vyčteny důležité informace, jako jsou adresy a částky k fakturaci. Jsou rozpoznány jednotlivé částky, z kterých se faktura skládá „tzv. line itemy“ a prezentovány ve formě tabulek. Jistota, s kterou poskytovatel rozpoznal konkrétní informaci je předložena ve formě „confidence“. Nutno říct, že tento údaj není absolutní, protože si poskytovatelé přesnost počítají svými algoritmy. Obecně s vyšší „confidence“ roste i přesnost rozpoznané informace. My jsme přesnost zkoumali na předpřipravených fakturačních modelech, které Azure poskytuje a které lze využít k rozpoznání obecných faktur. Pokud bychom chtěli zvýšit přesnost na konkrétních fakturách zákazníků, můžeme si natrénovat vlastní modely.
Modely: Jak už vyplývá z předešlých odstavců, Microsoft poskytuje předtrénované modely, které lze použít k extrakci informací. Kromě modelů faktur se jedná o stvrzenky, identifikační dokumenty (pas, občanka …), zdravotnické karty, daňové formuláře a další.
Extrakce v Azure prakticky
Pro účely datové extrakce je nutné vytvořit pouze dva zdroje. Storage jako datové úložiště a Document Intelligence pro rozpoznávání dokumentů. Proces vytváření zdrojů je intuitivní.
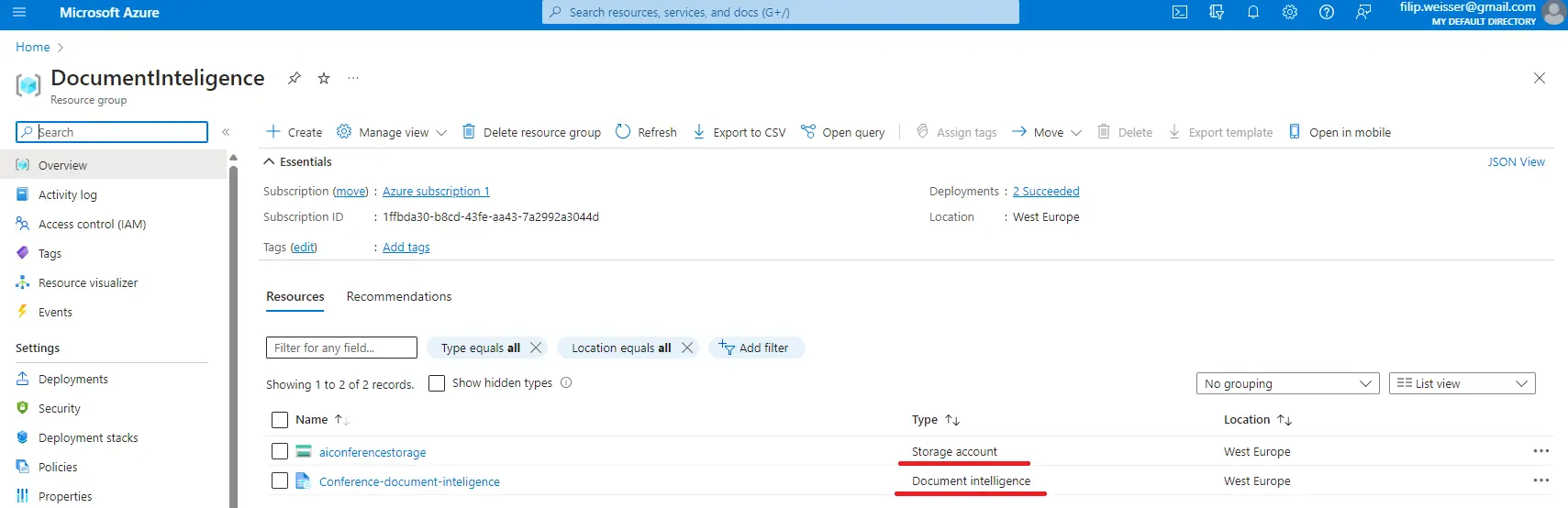
Document Intelligence Studio
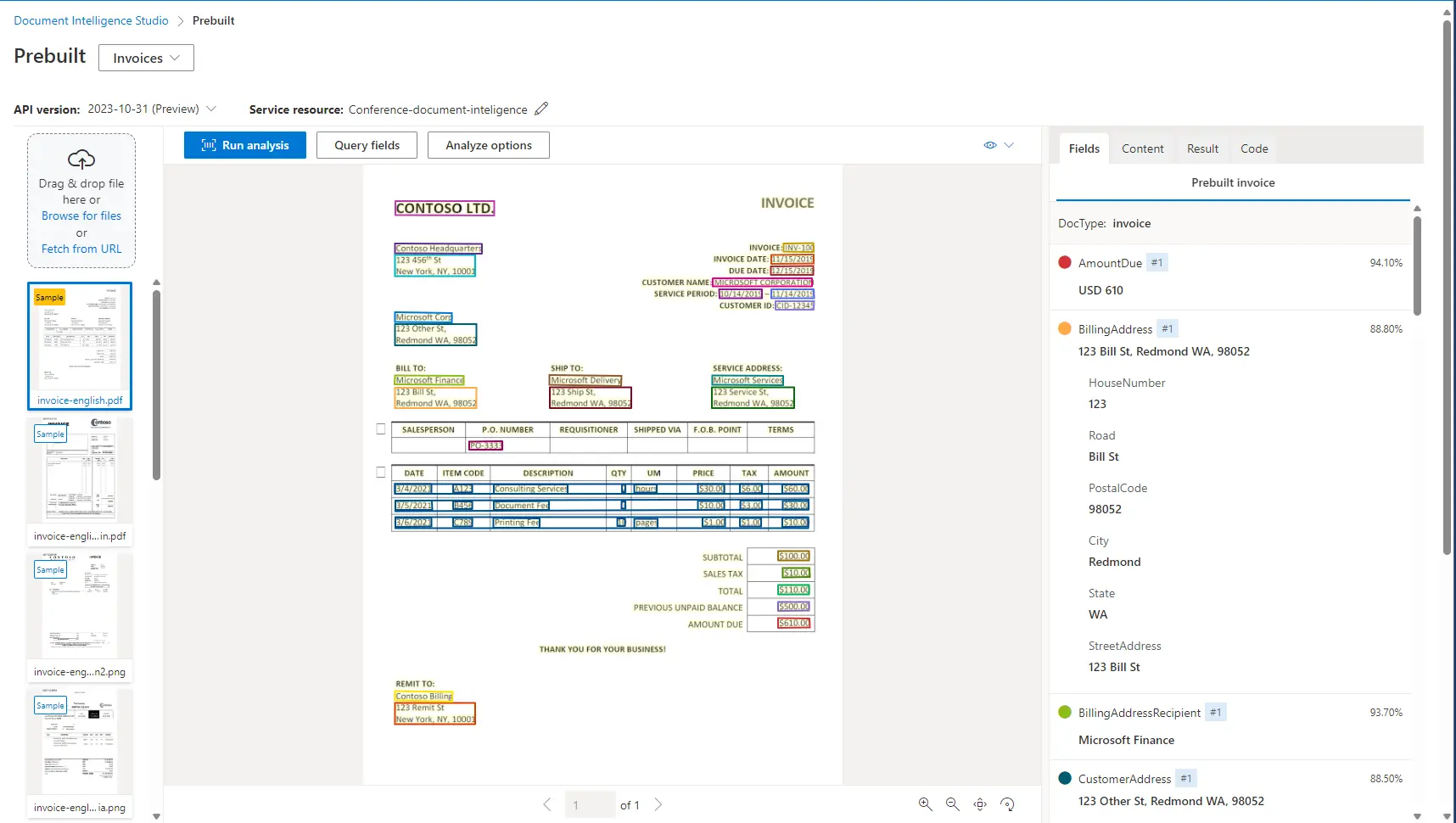
Azure nabízí UI rozhraní, ve kterém lze provádět datovou extrakci. Můžeme si snadno a rychle vyzkoušet varianty, které pro naše účely potřebujeme. Rozhraní najdeme po otevření Document Intelligence zdroje na hlavní stránce pod názvem Document Intelligence Studio. Zde je příklad rozpoznané faktury:
Kromě rozpoznávání dokumentů si v uživatelském rozhraní můžeme také natrénovat a otestovat vlastní modely.
A co použití v mé aplikaci?
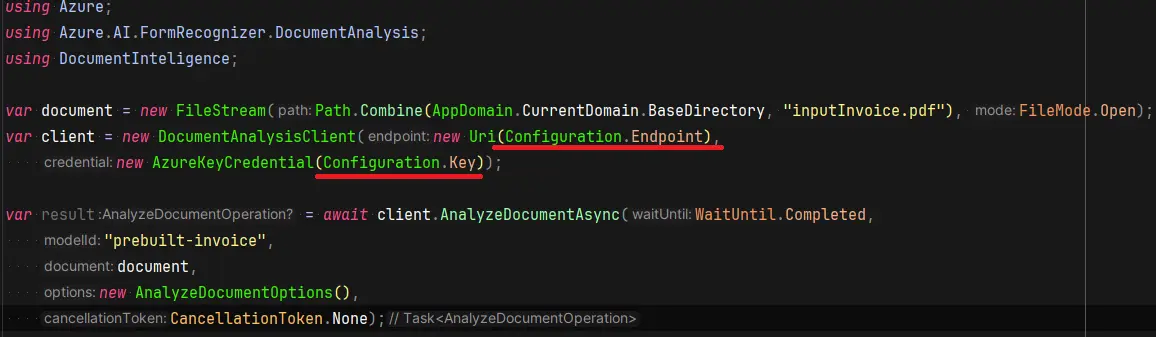
Microsoft poskytuje balíčky pro C#, Python, Javu a Javascript. Pro použití v dalších jazycích je dostupné REST API. Zde je příklad pro C#.
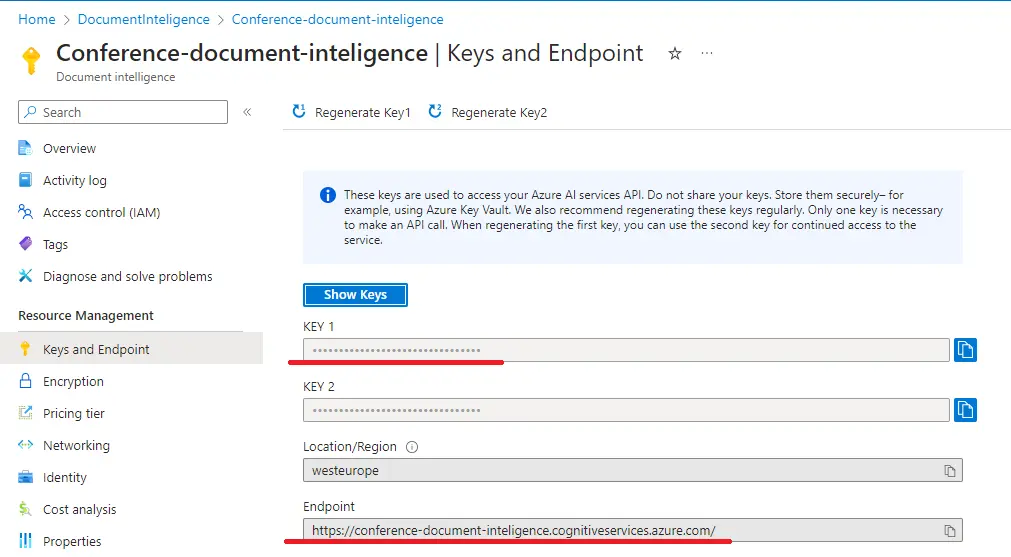
Pro vytvoření klienta z balíčku je nutné poskytnout adresu zdroje a informaci pro autorizaci. Vše najdeme v Azure portálu pod vytvořeným zdrojem. Můžeme se také autorizovat s použitím managed identity a dalších autorizačních mechanismů.
Potencionální problémy
Doufám, že z řádků výše vyplývá, že vyčítání informací z dokumentů je intuitivní a můžeme ji do našich aplikací integrovat i bez znalostí umělé inteligence a algoritmů pro extrakci. Tímto bych chtěl všechny motivovat k prozkoumávání existujících řešení, které mohou pozvednout úroveň a zjednodušit používání našich aplikací. My při integraci narazili na některé problémy, které bych rád zmínil.
Rychlost: při zpracování velkého množství dokumentů je nutné počítat se škálováním. Zpracování jednostránkového dokumentu trvá nižší jednotky sekund.
Serializace: Výsledek s extrahovanými daty nelze v C# znovu serializovat do objektu, který Azure balíček poskytuje. To může být problém například u testování, kde nejsme schopni data v JSONu reprezentovat znovu do objektu, který chceme otestovat.
Balíčky: Pro C# nyní existují dva balíčky, které jsou ekvivalentní. K FormRecognzer balíčku přibyl DocumentIntelligence balíček. V budoucnu dojde pravděpodobně k nahrazení FormRecognizer balíčku, což by neměl být problém, neboť jsou oba zpětně kompatibilní.
Formát faktury: Společnosti, které zpracovávají faktury požadují na vstupu standardizované formáty jako jsou CII, UBL apod. Na tyto formáty je nutné výsledek rozpoznané faktury převést v naší aplikaci.