
At Quadient, we aim to simplify communication and information sharing for users across various platforms by automating processes, saving their valuable time. One of the activities that customers had to do manually is extracting information from documents.
There are several algorithms that extract information from documents. This post targets people looking for a quick and financially accessible way to extract data from documents without delving into the intricacies of data extraction or needing extensive knowledge of artificial intelligence.
How to choose?
Market leaders in software offer ready-made solutions for data extraction. This section compares services from Microsoft, AWS, Google, and Rossum. See the table below for which providers met our requirements for the metrics we set.
The only solution that did not meet our requirements for extraction accuracy was AWS. For our purposes - recognizing information from invoices - we chose Microsoft. More detailed information was presented at our MeetinQ #2 titled AI in development. Here are the results from Microsoft for invoice recognition.
Price: For pre-prepared models, the price of recognized documents is around $10 for 1000 pages. For user-created models, the price is approximately $50 for 1000 pages. The price decreases with the number of pages processed. You can calculate an approximate amount in the Azure calculator.
Output: All providers, including Azure, return results in JSON format, making it possible to serialize information into application objects and work with them further. Specific information about JSON elements can be found in the documentation.
Accuracy: Microsoft's recognition of information, along with other providers except AWS, yielded interesting results. In most cases, crucial invoice details such as addresses and billing amounts are extracted from invoices. Individual amounts from which the invoice is composed, the so-called "line items," are recognized and presented in tables. The confidence with which the provider recognized specific information is presented in the form of "confidence." It is worth noting that this data is not absolute, as providers calculate accuracy with their algorithms. Generally, higher "confidence" leads to more accurate recognized information. We examined accuracy on pre-prepared billing models provided by Azure, which can be used for general invoice recognition. If we wanted to increase accuracy on specific customer invoices, we could train our own models.
Models: As evident from the preceding paragraphs, Microsoft provides pre-trained models that can be used for information extraction. In addition to invoice models, there are receipts, identification documents (passport, ID card, etc.), medical cards, tax forms, and more.
Azure Extraction in Practice
For data extraction purposes, only two resources need to be created: Storage as a data repository and Document Intelligence for document recognition. The process of creating resources is intuitive.
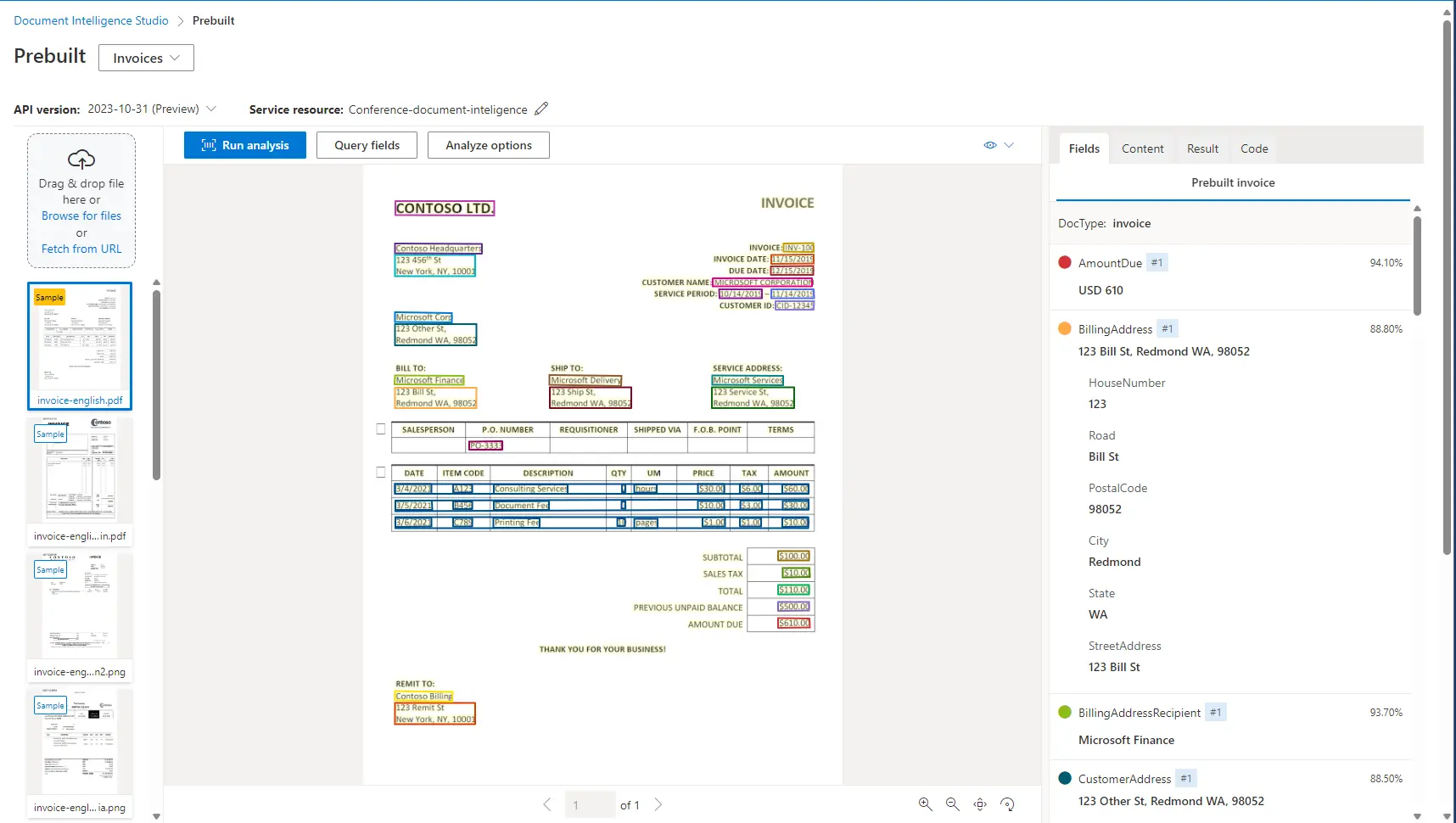
Document Intelligence Studio
Azure offers a UI interface for performing data extraction. We can easily and quickly test variants needed for our purposes. The interface can be found by opening the Document Intelligence resource on the main page under the name Document Intelligence Studio. Here is an example of a recognized invoice: In addition to document recognition, we can also train and test custom models in the user interface.
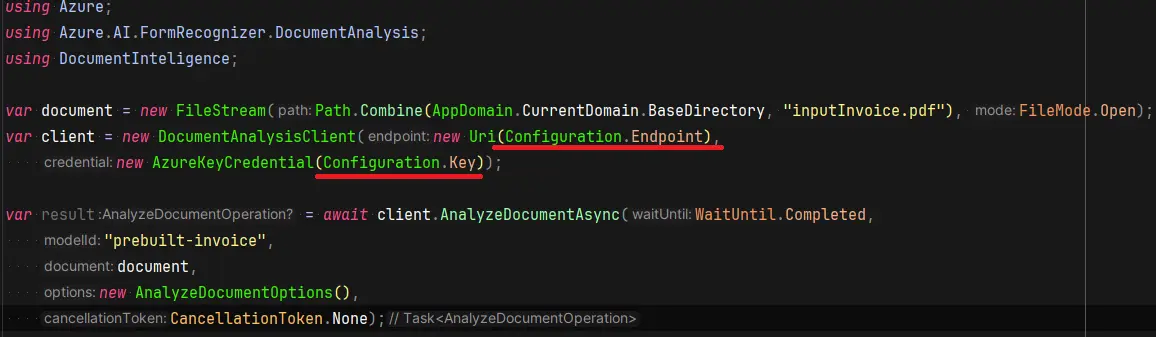
Integration into My Application
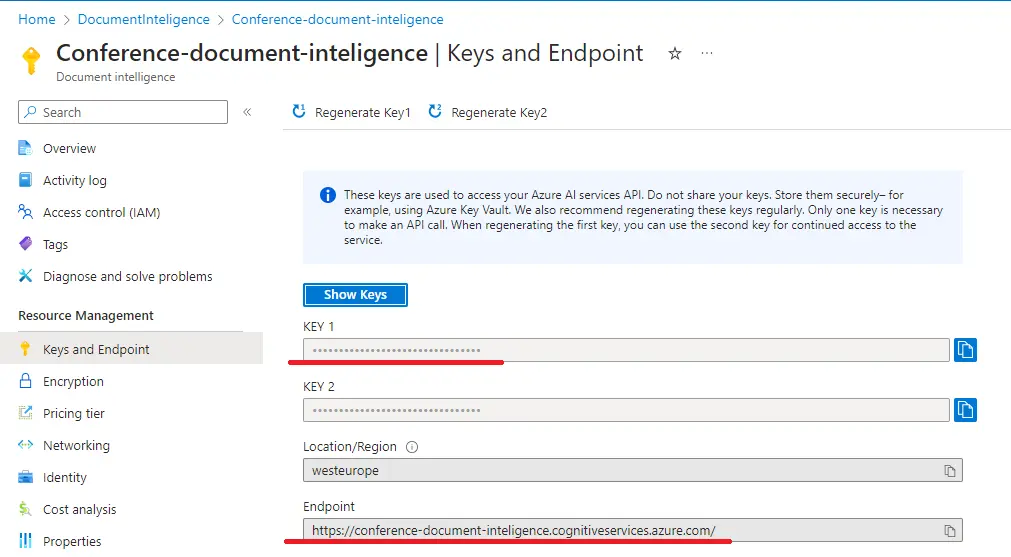
Microsoft provides packages for C#, Python, Java, and JavaScript. For use in other languages, a REST API is available. Here is an example for C#. To create a client from the package, it is necessary to provide the source address and authorization information. Everything can be found in the Azure portal under the created resource. Authorization can also be done using managed identity and other authorization mechanisms.
Potential Issues
I hope it is clear from the above lines that extracting information from documents is intuitive and can be integrated into our applications even without knowledge of artificial intelligence and extraction algorithms. I would like to motivate everyone to explore existing solutions that can elevate the level and simplify the use of our applications. During integration, we encountered some issues that I would like to mention.
Speed: When processing a large number of documents, scaling must be considered. Processing a single-page document takes a lower unit of seconds.
Serialization: The result with extracted data cannot be re-serialized into an object provided by the Azure package in C#. This can be a problem, for example, in testing, where we are unable to represent JSON data back into an object that we want to test.
Packages: For C#, there are currently two packages that are equivalent. The DocumentIntelligence package has been added to the FormRecognizer package. In the future, FormRecognizer package is likely to be replaced, which should not be a problem as both are backward compatible.
Invoice Format: Companies processing invoices require standardized formats such as CII, UBL, etc., as input. The result of the recognized invoice needs to be converted into these formats in our application.